
최근들어 코로나 재확산이 심각해지면서 공공데이터API를 이용하여 데일리로 확진자 증감률을 계산해봤습니다.
공공데이터포털 사이트(https://data.go.kr/index.do)에 가서 코로나19로 검색해서 찾은 API를 이용했습니다.
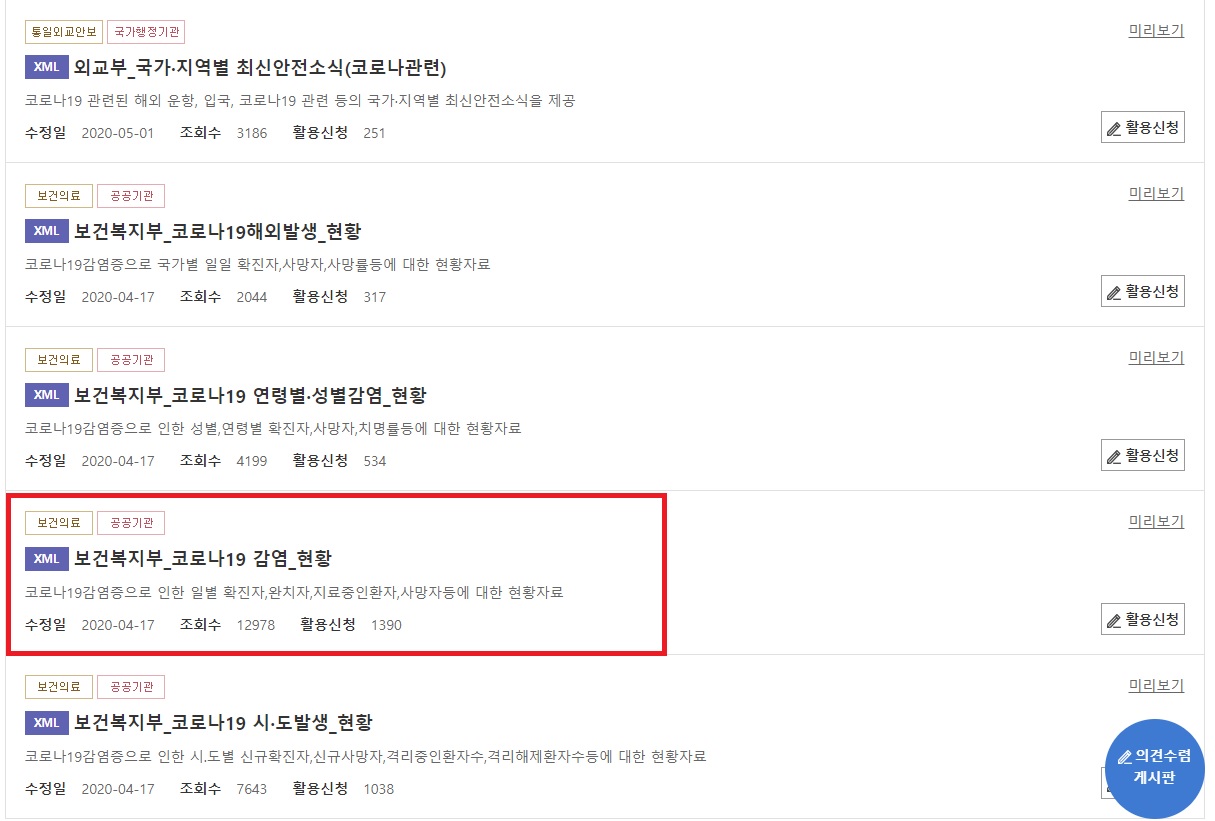
언어는 Python을 이용했습니다. 먼저 api문서명세대로 get요청을 날려서 데이터를 받습니다.
#서비스url
serviceUrl = 'http://openapi.data.go.kr/openapi/service/rest/Covid19/getCovid19InfStateJson'
#인증키
serviceKey = '여기에 본인이 받은 인증키를 string으로 적으세요'
#서비스키가 utf8로 인코딩되어 있어서 unquote로 디코딩에서 get요청을 보내야 응답이 정상적으로 옵니다.
serviceKey_decode=unquote(serviceKey)
pageNo = '1'
numOfRows = '10'
startCreateDt = '20200501'
endCreateDt = time.strftime('%Y%m%d',time.localtime(time.time()))
#api문서대로 파라미터를 설정합니다.
parameters = {"serviceKey":serviceKey_decode,"pageNo":pageNo,"numOfRows":numOfRows,"startCreateDt":startCreateDt,"endCreateDt":endCreateDt}
#get요청을 보냅니다.
response = requests.get(serviceUrl,params=parameters)
#xml형태이고 String객체로 받아온것을 알 수 있습니다.
print(response.text)
*여기서 주의할 점은 서비스키를 디코딩해서 get요청을 보내야합니다.
위 코드대로 한다면
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><response><header><resultCode>00</resultCode><resultMsg>NORMAL SERVICE.</resultMsg></header><body><items><item><accDefRate>1.0613728954</accDefRate><accExamCnt>2000552</accExamCnt><accExamCompCnt>1945028</accExamCompCnt><careCnt>4786</careCnt><clearCnt>15529</clearCnt><createDt>2020-09-03 09:37:35.778</createDt><deathCnt>329</deathCnt><decideCnt>20644</decideCnt><examCnt>55524</examCnt><resutlNegCnt>1924384</resutlNegCnt><seq>250</seq><stateDt>20200903</stateDt><stateTime>00:00</stateTime><updateDt>null</updateDt></item>.....생략...</body></response>
이런식으로 응답이 오는것을 확인할 수 있습니다.
startCreateDt와 endCreateDt변수값을 조절한다면 특정 날짜사이의 데이터를 구할 수 있습니다.
어쩄든 xml형태로는 데이터를 구분하기 어려우니 xml파서를 이용해서 이쁘게 정재해 보도록 하겠습니다.
#200이면 서버응답이 제대로 되었다는 뜻
if response.status_code==200:
#xml파서객체로 받아온다
tree=el.fromstring(response.text)
#item태그 사이에 있는 모든태그들을 iter로 받아옴
iter=tree.iter(tag="item")
str = ''
#iter로 순회하면서 데이터를 읽어옵니다.
for element in iter:
createDt = element.find('createDt') #일시
accExamCnt = element.find('accExamCnt') #누적검사수
accExamCompCnt = element.find('accExamCompCnt') #누적검사완료수
examCnt = element.find('examCnt') #검사진행
resutlNegCnt = element.find('resutlNegCnt') #음성수
decideCnt = element.find('decideCnt') #확진자
careCnt = element.find('careCnt') #치료중
clearCnt = element.find('clearCnt') #격리해제
deathCnt = element.find('deathCnt') #사망자
str+="{} 기준 \n 누적검사수 : {} \n 검사완료 : {} - 검사진행중 : {} \n 음성판정 : {}, 확진자 : {} \n 치료진행중 : {}, 사망자 : {}, 격리해제자 : {} \n\n".format\
(createDt.text,accExamCnt.text,accExamCompCnt.text,examCnt.text,resutlNegCnt.text,decideCnt.text,careCnt.text,deathCnt.text,clearCnt.text)
print(str)
위 코드대로 한다면
2020-09-03 09:37:35.778 기준
누적검사수 : 2000552
검사완료 : 1945028 - 검사진행중 : 55524
음성판정 : 1924384, 확진자 : 20644
치료진행중 : 4786, 사망자 : 329, 격리해제자 : 15529
이런식으로 데일리로 확진자 사망자 격리해제자 등등 데이터를 알 수 있습니다.
이제 데일리로 확진자 증감률을 확인해 보겠습니다. 위코드에서 몇줄만 추가해주면 됩니다.
if response.status_code==200:
#print("응닫결과 : ",response.text)
tree=el.fromstring(response.text)
iter=tree.iter(tag="item")
str = ''
dateList = []
decideList=[]
deathList=[]
clearList=[]
accExamList=[]
for element in iter:
createDt = element.find('createDt') #일시
accExamCnt = element.find('accExamCnt') #누적검사수
accExamCompCnt = element.find('accExamCompCnt') #누적검사완료수
examCnt = element.find('examCnt') #검사진행
resutlNegCnt = element.find('resutlNegCnt') #음성수
decideCnt = element.find('decideCnt') #확진자
careCnt = element.find('careCnt') #치료중
clearCnt = element.find('clearCnt') #격리해제
deathCnt = element.find('deathCnt') #사망자
#추가되는 부분
dt = parse(createDt.text)
dateList.append(dt.date())
decideList.append(decideCnt.text)
str+="{} 기준 \n 누적검사수 : {} \n 검사완료 : {} - 검사진행중 : {} \n 음성판정 : {}, 확진자 : {} \n 치료진행중 : {}, 사망자 : {}, 격리해제자 : {} \n\n".format\
(createDt.text,accExamCnt.text,accExamCompCnt.text,examCnt.text,resutlNegCnt.text,decideCnt.text,careCnt.text,deathCnt.text,clearCnt.text)
print(str)
#추가되는 부분
dateList.reverse()
decideList.reverse()
length = len(decideList)
for index in range(length-1):
a = int(decideList[index])
b = int(decideList[index + 1])
res = ((b - a) / a) * 100
print(dateList[index+1]," : ",res)
위코드를 실행시킨다면 아래처럼 데일리로 증감률이 나오게됩니다.
여기서 눈여겨볼만한 부분이 8월 15일 기준으로 0.5%정도하던 확진자 증가율이 1.5%~2%가까이 늘어나는 것을 확인 할 수있습니다. 즉, 뉴스에서 말하던 더플링현상이 가속된것임을 알 수있습니다 ㅎㅎ
2020-05-02 : 0.055689623166883244
2020-05-03 : 0.12059369202226346
2020-05-04 : 0.07412211618641712
....생략....
2020-08-10 : 0.1918070968625839
2020-08-11 : 0.2324627375905921
2020-08-12 : 0.36834924965893584
2020-08-13 : 0.3805899143672693
2020-08-14 : 0.6973595125253893
2020-08-15 : 1.1161164526322866 -- 여기서 부터 갑자기 1%대 유지시작.. ㄷㄷㄷㄷ
2020-08-16 : 1.8551765409934171
2020-08-18 : 1.2860686773730252
2020-08-18 : 1.5855623590074122
2020-08-19 : 1.8843981980838782
2020-08-20 : 1.7934985676921162
2020-08-21 : 1.9821363024593173
2020-08-22 : 1.9916016796640672
2020-08-23 : 2.3350194094812373
2020-08-24 : 1.5288234956031956
2020-08-25 : 1.5850551938862156
2020-08-26 : 1.783226525494567
2020-08-27 : 2.4144538735286063
2020-08-28 : 1.9833208596172351
2020-08-29 : 1.6931383341196204
2020-08-30 : 1.541237113402062
2020-08-31 : 1.2589471546779025
2020-09-01 : 1.1781220233619092
2020-09-02 : 1.3229610544049153
2020-09-03 : 0.9535918626827717
그리고 여기서 matplotlib을 이용해서 데이터 시각화를 나름 해보았으나...

음 뭔가 이쁘게 나오지는 않습니다 ㅎㅎ.
어쨋거나 공공데이터API를 이용해서 확인해보니 데이터는 거짓말을 하지 않는다는 것을 알수 있군요!
아무쪼록 부족한 글 봐주셔서 감사하고 모두 코로나 조심하세요~
아래는 전체 코드입니다~
import requests
import time
from dateutil.parser import parse
from urllib.parse import unquote
import xml.etree.ElementTree as el
from matplotlib import pyplot as plt
serviceUrl = 'http://openapi.data.go.kr/openapi/service/rest/Covid19/getCovid19InfStateJson'
serviceKey = '서비스키는 각자 알아서 ^-^'
serviceKey_decode=unquote(serviceKey)
pageNo = '2'
numOfRows = '10'
startCreateDt = '20200501'
endCreateDt = time.strftime('%Y%m%d',time.localtime(time.time()))
parameters = {"serviceKey":serviceKey_decode,"pageNo":pageNo,"numOfRows":numOfRows,"startCreateDt":startCreateDt,"endCreateDt":endCreateDt}
response = requests.get(serviceUrl,params=parameters)
print(response.text)
if response.status_code==200:
#print("응닫결과 : ",response.text)
tree=el.fromstring(response.text)
iter=tree.iter(tag="item")
str = ''
dateList = []
decideList=[]
deathList=[]
clearList=[]
accExamList=[]
for element in iter:
createDt = element.find('createDt') #일시
accExamCnt = element.find('accExamCnt') #누적검사수
accExamCompCnt = element.find('accExamCompCnt') #누적검사완료수
examCnt = element.find('examCnt') #검사진행
resutlNegCnt = element.find('resutlNegCnt') #음성수
decideCnt = element.find('decideCnt') #확진자
careCnt = element.find('careCnt') #치료중
clearCnt = element.find('clearCnt') #격리해제
deathCnt = element.find('deathCnt') #사망자
dt = parse(createDt.text)
dateList.append(dt.date())
decideList.append(decideCnt.text)
deathList.append(deathCnt.text)
clearList.append(clearCnt.text)
accExamList.append(accExamCnt.text)
str+="{} 기준 \n 누적검사수 : {} \n 검사완료 : {} - 검사진행중 : {} \n 음성판정 : {}, 확진자 : {} \n 치료진행중 : {}, 사망자 : {}, 격리해제자 : {} \n\n".format\
(createDt.text,accExamCnt.text,accExamCompCnt.text,examCnt.text,resutlNegCnt.text,decideCnt.text,careCnt.text,deathCnt.text,clearCnt.text)
print(str)
dateList.reverse()
decideList.reverse()
deathList.reverse()
clearList.reverse()
accExamList.reverse()
#print(dateList)
#print(decideList)
length = len(decideList)
for index in range(length-1):
a = int(decideList[index])
b = int(decideList[index + 1])
res = ((b - a) / a) * 100
print(dateList[index+1]," : ",res)
plt.figure(figsize=(16, 8))
plt.subplot(221)
plt.plot(dateList,decideList,'r', label='decide')
plt.legend(['decide'])
plt.title('decide')
plt.subplot(222)
plt.plot(dateList, deathList,'black', label='death')
plt.legend(['death'])
plt.title('death')
plt.subplot(223)
plt.plot(dateList, clearList,'b', label='clear')
plt.legend(['clear'])
plt.title('clear')
plt.subplot(224)
plt.plot(dateList, accExamList, 'green', label='accCnt')
plt.legend(['accCnt'])
plt.title('accCnt')
plt.subplots_adjust(wspace=0.35)
plt.show()